G2_5 Graphique 2.5. Taux de chômage par catégorie
socioprofessionnelle 1962-2011
Tout comme la
série de graphiques G2_6 G2_7 G2_8 et
G3_3
Graphique 2.6. Part des différentes catégories
socioprofessionnelles dans la population active 1962-2011
Graphique 2.7. Part des diplômés de différents
niveaux en emploi cadre ou profession intermédiaire 1962-2011 (population âgée
de 25 à 34 ans)
Graphique 2.8. Pourcentage empirique et théorique
(sous hypothèse de maintien de la valeur des diplômes depuis 1982) de cadres et
professions intellectuelles supérieures (CPIS=classes moyennes supérieures) et
de CPIS et professions intermédiaires (CPIS-PI = classes moyennes supérieures
et intermédiaires)
Ainsi que :
Graphique 3.3. Effet de la cohorte de naissance sur
le prestige selon le diplôme – résultat du modèle APCT
Je me fonde sur
la source d’extraits des Recensement français de l’INSEE harmonisés par le
projet Ipums
https://international.ipums.org/international/
que l’on cite
ainsi :
Minnesota
Population Center. Integrated
Public Use Microdata Series, International: Version 6.4 [Machine-readable database].
Minneapolis: University
of Minnesota, 2015.
Je précise
rapidement que j’utilise cet extrait car les américains ont une culture
d’harmonisation des données que l’on ne trouve pas en France, pour l’heure.
L’INSEE d’un côté et surtout le centre Quételet (www.reseau-quetelet.cnrs.fr/) de l’autre, font un bon travail
mais aucun ne produit de bon ficher harmonisé de long terme susceptible de
faire autorité. L’INSEE s’y essaie (Données harmonisées des recensements de la
population 1968-2012
http://www.insee.fr/fr/themes/detail.asp?reg_id=0&ref_id=fd-rp19682012)
mais ces extraits ne permettent pas d’aller aussi loin que l’extrait Ipums qui propose beaucoup plus de variables nettement plus
détaillées. C’est un peu humiliant mais cela aide à réfléchir aux pratiques
françaises : l’administrateur INSEE étant en poste trois ans, le long
terme et l’harmonisation sur des décennies, vous savez...
·
Pour
réaliser cette série de traitements, il faut d’abord un compte ipumsi, ce qui s’obtient par enregistrement (Apply for access) ici :
https://international.ipums.org/international-action/menu
Une fois les
droits obtenus (je ne m’étends pas sur l’ergonomie), il s’agit de constituer un
extrait avec les variables suivantes :
(on peut être plus parcimonieux, mais cet extrait permet de
développer d’autres recherches)
country year sample serial persons urban enuts2 geo1_fr ownership ownershipd autos rooms hhtype pernum perwt relate related age sex marst marstd educfr empstat empstatd occisco occ isco88a ind classwk classwkd fr1962a_occ fr1962a_soccup fr1968a_occ fr1968a_socc fr1975a_occ fr1975a_socc fr1982a_occ fr1982a_socc fr1990a_occ fr1990a_socc fr1999a_occ fr1999a_occty fr1999a_indciti fr2006a_socio24 fr2006a_socio42 fr2006a_prof486 fr2006a_prof486n fr2011a_occ24 fr2011a_occ fr2011a_profs fr2011a_prof fr2011a_prof2
Cela représente
52 variables, et 8 recensements. Pour gagner du temps et de l’espace disque,
j’ai demandé pour chaque année un extrait de densité 1% (autrement dit un
tirage probabiliste uniforme de un résident de métropole sur cent), une
sélection qui peut s’opérer en sollicitant le bouton « customize
sample size » de la fenêtre idoine. Nous aurons
donc des échantillons dont la taille vaut en moyenne un demi-million
d’individus par année de recensement.
Si vraiment vous
ne réussissez pas, faites-moi signe (chauvel@louischauvel.org).
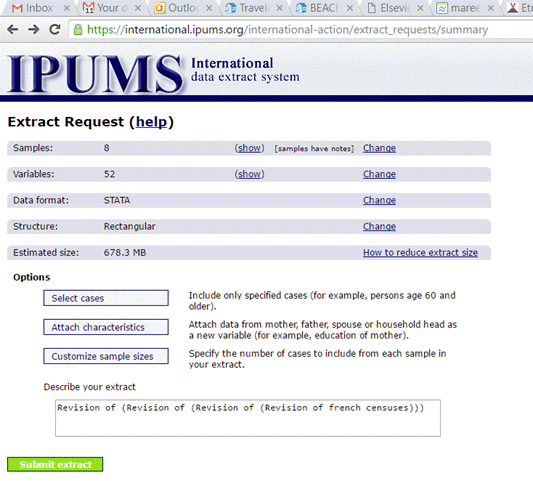
En soumettant
cette requête, vous obtiendrez un fichier STATA compressé en format zip, que
vous pourrez télécharger puis décompresser sur votre répertoire de travail.
Pour ma part, je réalise tous mes gros calculs sur le répertoire C:\tmp\ de mon
disque.
Les graphiques
résultent des tables calculées par le programme http://www.louischauvel.org/G2_5sqq.do
exécuté dans STATA.